Deep Learning在CTR预估方面的应用
在广告rank、搜索rank和推荐rank等方向,CTR预估都是其中非常重要的一个模块。以广告rank为例,记 \(pctr\) 表示predicted CTR,即预估CTR,\(bid\) 表示bid price,即出价,那么 \(pctr * bid\) 就能得到单位流量上的广告营收,这个乘积反映了流量的变现效率。不同于搜索rank和推荐rank,大部分情况下这两者只需要关注 \(pctr\) 的序别是对的即可,而广告rank中对点击率预估要求更高些,需要给出精准的点击概率 \(pctr\) ,因为只有是把精准预估出的 \(pctr\) 和出价 \(bid\) 相乘,才能让用户、广告主和广告平台三方的整体收益最大。
对广告CTR预估问题,最早是基于LR模型(是一种浅层模型),从用户、广告主、上下文环境三方面着手做大量的特征工程,而且一般需要加入特征之间的非线性关系,比如使用特征交叉,引入GBDT等技巧。因为不是所有的特征之间都需要加入非线性关系,所以这就需要不断地做实验来验证,时间代价较大。后来有了FM模型,也就是factorization machine(也是一种浅层模型),通过两两向量之间的点积来判断特征之间和目标变量之间的关系,这就让特征间的非线性关系交由FM模型来处理,省去了调试非线性关系的实验时间。近几年,deep learning技术也逐渐引入到CTR预估中,而且已经有不少DL模型用于线上广告rank服务了。有几篇关于FNN和PNN的文章,这两个模型与FM模型有一定的联系,那就是用FM训出的模型作为神经网络的embedding层。
FM模型的model function如图1所示,其由两部分组成,前一部分与LR模型的model function一样,后一部分是给每一维特征用一个向量表示,以向量间的点积来描述特征之间和目标变量之间的关系。经过训练可以得到模型参数,这后一部分的向量就可以视为各个特征的embedding向量,即得到特征的embedding表示。正因为此,倘若站在神经网络的角度看FM模型,我们可以视其为3层神经网络,如图2所示,最底层是embedding层,含有要学习的模型参数,中间一层是inner product层,没有要学习的参数,最顶层就是一个普通的先sigma求和后求sigmoid的神经元。需要学习的参数只有最底层。
说明:图2的隐藏层在画法上有一点错误。Embedding层的 \(w_i\) 和 \(w_j\) 应该连接到隐藏层的不同节点,而不是同一个节点。(注意看FM模型的LR那部分)
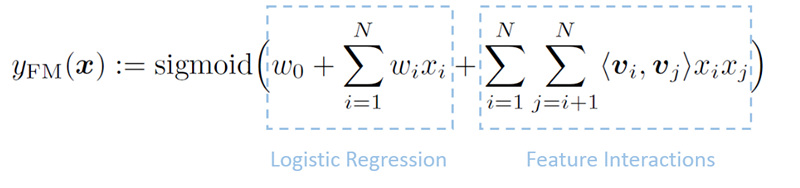
图1 FM模型的model function
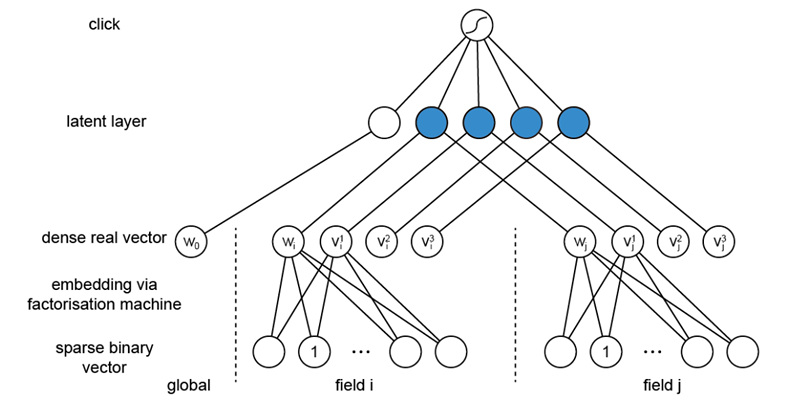
图2 FM模型等价于3层神经网络
既然可以把FM模型当做一个3层神经网络,而且FM模型就是只训练了最底层的embedding层,那么站在神经网络的角度去思考,就可以引出接下里的FNN模型,如图3所示。FNN全称 Factorization-machine supported Neural Networks。底层还是embedding层,而且就用FM模型做训练得到各个输入特征的embedding向量。中间2层是普通的全连接网络层,最顶层就是普通的sigmoid神经元。跟FM不同的地方在于,1)引入了全连接层代替了inner product层;2)中间层和顶层都引入了模型参数。直觉上看这个模型的表达能力更强,如果训练语料足够丰富,是可以达到比FM模型更好的效果。在360广告CTR预估业务上,就用FNN模型取得了不错的结果。
在FNN的embedding层上加一个product层,就得到了PNN模型,如图4所示。
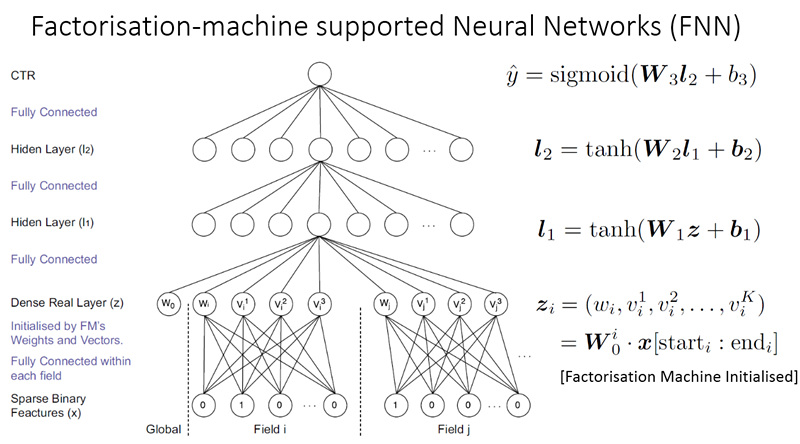
图3 FNN模型
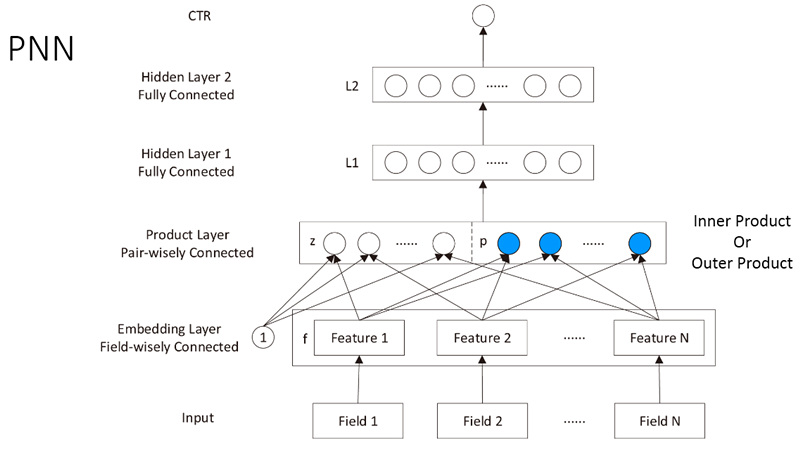
图4 PNN模型
相关文献
- Deep Learning over Multi-Field Categorical Data: A Case Study on User Response Prediction
- 介绍FNN模型。将FM模型训出的结果作为其中的embedding层,上面套上全连接神经网络。
- Product-based Neural Networks for User Response Predictions
- 介绍PNN模型。在FNN的embedding层的上面加入produce层,往上还是用全连接神经网络。
- Wide & Deep Learning for Recommender Systems
- Google提出的wide和deep learning模型。
- 用户在线广告点击行为预测的深度学习模型
- 这是来自张伟楠博士在携程技术中心主办的深度学习Meetup中的主题演讲。张伟楠博士现在是上海交大的助理教授,其个人主页是 http://wnzhang.net/,他是FNN和PNN的主要作者,还是SVDFeature的作者之一,11年和12年的KDD Cup都有他的身影。
- 闲聊DNN CTR预估模型
- 作者 Kintocai (蔡建涛,来自腾讯)
- 这篇文章写得非常好,而且还有作者的一些精辟分析和实践经验,特别是在最后给出了一个总结性的框架图,将这些模型以及一些连续特征的处理方法统一到一个整体框架中,非常赞。
- 很同意作者的好几个观点,比如:
- 在训练样本量足够的情况下,尽可能用简单一些的模型,减少inference的计算量,提高计算的吞吐量,大数据本身就可以解决很多问题。
- 离散LR依然是二分类问题场景的首选方案,LR加上良好的特征工程足以解决大部分实际问题。
- 不过对于dropout的使用,个人觉得在全连接层适当使用dropout是有用的,它可以在一定程度防止模型的过拟合。当然如果是训练数据量较大,特征维度较少时,dropout不是必需的。
原创文章,转载请注明:转载自vividfree的博客
本文链接地址:201704 阅读笔记