Node2Vec
在实际工作中,我们时常会碰到这样一些问题,它们可以用图来建模,比如社交网络,网页间的互相链接,query到URL或者到app的点击二部图,蛋白质之间的作用网络(PPI, Protein-Protein Interactions)。在图上,我们会有一些预测节点类型或者边类型的需求。比如社交网络上某些网民填了体育等兴趣标签,但还有很多网民没填兴趣标签,但可能对体育或者其他兴趣感兴趣。我们是否可以预测出全部网民的兴趣,这就是社交网络中一个代表性问题。
对于上述这样的预测需求,我们可以建模为有监督学习问题(比如分类),也可以建模为半监督问题(比如label propagation方法)。不管是哪种建模,它们中的大部分方法需要提取特征,甚至是做feature learning。2016年7月,斯坦福大学的2个学者提出node2vec方法,不仅可以有效的做feature learning,对节点算出embedding向量,而且这embedding向量还能最终改进预测问题的效果。下面给出文章链接,并简要介绍node2vec这种node embedding方法。
- node2vec: Scalable Feature Learning for Networks
- 对每个节点,基于随机游走产出一段路径。有了很多这样的路径后,就可以用类似于word2vec的处理办法生成node的embedding。说明:这些路径可以视为是一种节点序列,所以下一步用word2vec处理也是比较自然的想法。
- 在随机游走方面,做了一些创新和加强,尝试做一种介于DFS和BFS的路径搜索办法,具体是通过引入p,q两个超参数来控制(p,q两个超参数的取值通过验证集来选)
基于深度学习的文本匹配
自然语言处理的许多任务,例如信息检索、自动问答、机器翻译、对话系统、复述问题等等,都可以抽象成文本匹配问题。处理文本匹配的传统方法主要集中在人工定义特征之上的关系学习,模型的效果很大程度上依赖于特征工程,传统模型在一个任务上表现很好的特征很难用到其他文本匹配任务上。而深度学习可以自动从原始数据中抽取特征,免去了大量人工设计特征的开销。所以近几年大量基于深度学习的文本匹配方法被提出。相比于传统方法,深度学习方法除了可以从大量的样本中自动提取出词语之间的关系,并能结合短语匹配中的结构信息和文本匹配的层次化特征,更精细地描述文本匹配问题。
中科院计算所的徐君、庞亮以及百度NLP团队对基于深度学习的文本匹配写过一些综述性的材料。
- Deep Approaches to Semantic Matching for Text
- 作者:徐君
- 这是一篇关于基于深度学习的文本匹配的非常好的tutorial。其将基于深度学习的文本匹配方法分为2种:
- Composition focused methods: 图1是其框架图。先将每个句子转换为对应的embedding向量,然后度量两个embedding向量的相似度。总体框架或者说思路是这样的,虽然有很多模型可以归于这类,其中代表性的模型就有DSSM, CDSSM, ARC I, CNTN, LSTM-RNN,模型何其多,但它们无非是对第1步用MLP 还是用CNN 还是用RNN,对第2步度量相似度是用cos距离 还是用向量点积 还是用全连接网络 还是用张量神经网络(neural tensor netword,cos距离只是其一个特例)。联想起在之前的博客 201704 阅读笔记 介绍过DL在CTR预估中的应用,其中的PNN模型是在FNN的基础上将cos距离转换成全连接网络来做。技术是相通的,互相之间可以借鉴。
- Interaction focused methods: 这类方法认为做好文本匹配需要对各个粒度的语言对象(比如从词粒度到短语粒度到整个句子的粒度)之间的关系都要充分建模,所以提出先在最底层的语言粒度(比如词粒度,甚至是字粒度)上用其对应的embedding向量得出一个matching matrix ,然后用深度学习模型从中学习出匹配模式。图2是其框架图,代表性的模型有ARC II, MatchPynamid, Match-SRNN。
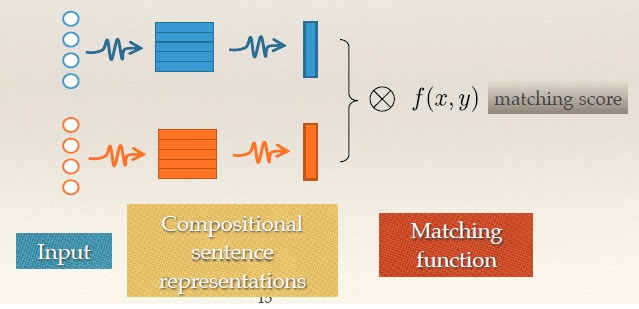
图1 Composition focused methods的框架图
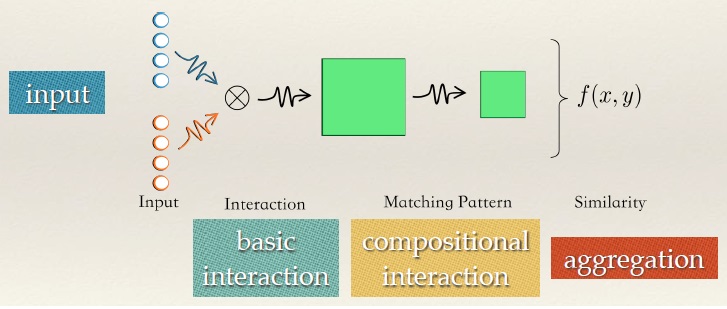
图2 Interaction focused methods的框架图
- 深度文本匹配综述
- 作者:庞亮等人,徐君是三作。这篇文章发表在计算机学报。
- 这篇文章也是将基于深度学习的文本匹配方法进行分类描述,不过这里分成3类,与徐君那个slide的区别在于,增加了基于多语义文档表达的类别,而该文章描述的基于单语义文档表达则可以对应到徐君那个slide的composition focused methods。图3介绍了每个类别下都有哪些模型。基于多语义的文档表达的深度学习模型认为单一粒度的向量来表示一段文本不够精细,需要多语义的建立表达,也就是分别提取词、短语、句子等不同级别的表达向量,再计算不同粒度向量间的相似度作为文本间的匹配度。其中的uRAE模型还需要依赖一个句法分析器,而目前句法分析器的准确性还不是特别高,因此该算法的鲁棒性不足。
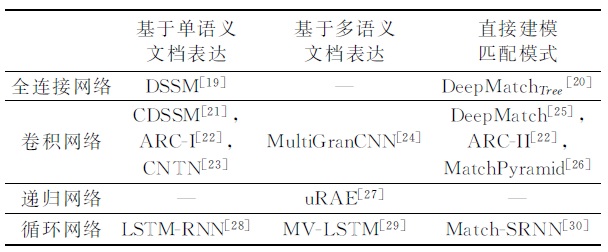
图3 深度文本匹配模型的分类
- 神经网络语义匹配技术
- 作者:百度NLP
- 核心模型方面跟前两篇文章差不多,但该文还站在实际应用层面介绍了一些细节处理策略,比如第3节介绍了一些改进点,比如中文字粒度匹配和多切分粒度融合,引入高频 Bigram 和 Collocation 片段。
上面几篇综述性材料帮助梳理了这个方面的研究脉络,有了这个基础后,再读相应的原始文献就比较轻松了(这些文章的作者主要来自Stanford, MSR, 华为诺亚方舟, 中科院计算所和复旦大学等科研机构)。读这些文章,还可以了解到将CNN模型应用于NLP问题,max pooling有哪些变种(比如 max pooling over time, k max pooling over time, chunk k max pooling over time, dynamic k max pooling),如何做模型的可视化(比如CDSSM, MatchPyramid, Match-SRNN等工作中在模型可视化方面有些工作)等细节处理办法。
在阅读提出CDSSM模型的paper A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval 时,了解到对于query到doc的相似性计算问题,在深度学习模型出来前,PTM(phrase based translation model)的效果(NDCG@1, NDCG@3, NDCG@10)最好。当前基于深度学习的文本匹配还没有idea是从翻译模型的思路来做,而深度学习已经验证了其在机器翻译中的效果,所以笔者认为用NMT(neural machine translation)的思路,即encoder-decoder框架,来做文本匹配可能也是一条合适的路子。
原创文章,转载请注明:转载自vividfree的博客
本文链接地址:201707 阅读笔记