Dropout
Dropout是深度学习里一种常用的正则化方法,它计算方便而且功能强大,并可以与L2参数范数惩罚、max-norm等正则化技术组合一起提高模型的泛化能力。
- Dropout: A simple way to prevent neural networks from overfitting
- Hinton组发表的paper,dropout方面最经典的文章,从bagging集成模型的角度介绍dropout是一种正则化方法。
- Dropout方法受生物学的想法启发:有性繁殖涉及到两个不同生物体之间交换基因,进化产生的压力使得基因不仅是良好的而且要准备好不同有机体之间的交换。这样的基因和这些特点对环境的变化是非常稳健的,因为它们一定会正确适应任何一个有机体或模型不寻常的特性。因此dropout正则化每个隐藏单元不仅是一个很好的特征,更要在许多情况下是良好的特征。通俗点讲就是,网络中每个节点的学习不要假设兄弟节点能够一直稳定的运行,这就要求各节点要更“努力”些,具有更强的能力。
- 在实际实现dropout时,一般会通过引入服从伯努利分布的随机mask来做,这个mask与激活函数的输出值相乘,如果mask的随机采样值为0,那么在正向传播(inference)和误差反向传播更新权重(即BP算法)时,该节点既不能带来分数上的贡献,而且其相关的边权重也不会被修改。
- 本文最精彩篇幅最大的地方就是在横跨 图像、语音、文本、基因 等多个数据集上取得了 当时的 state-of-the-art 结果或者次优解,足见这个方法的厉害之处。
- 还把dropout与bayesian neural networks对比。依贝叶斯理论,模型参数是有先验概率的,不同参数对应不同的模型,它们可以有不同的先验概率。贝叶斯理论用后验概率对问题建模。在这篇文章的实验中,dropout的效果并不比bayesian neural networks的效果差多少,但NN with dropout的训练和预测的速度都要快很多。
- 通过在验证集做实验,提出dropout的p(节点的保留概率)取值在0.5到0.8之间时模型的效果会比较好。
- Dropout as data augmentation
- 上一篇文章是从bagging集成方法的角度来介绍dropout可以防止过拟合,而这篇文章则是从数据增强的角度来介绍(在图像处理领域,数据增强是一种常用的正则化方法)。
- 文章的总体工作是:对于每一个dropout后的网络,进行训练时,相当于做了data augmentation,因为总可以找到一个样本,使得在原始的网络上也能达到dropout单元后的效果。
- Deep Learning
- 目前深度学习领域最深入的一本书,一共3位作者,他们是 Ian Goodfellow and Yoshua Bengio and Aaron Courville
- 其中的第7.12节介绍了dropout,主要是站在baggging角度系统总结了dropout的多种优点及其变种。
Dropconnect是LaCun组提出的一种对dropout的简单改进。这2种技术都用来防止过拟合,它们的区别大体在于,在训练过程中dropout是随机drop掉一些节点,而dropconnect则是随机drop掉一些边。因为目前实际中用dropout技术更多些,所以暂时没看dropconnect技术细节,这里就附上一份博文,将来再详细了解下。
Dropout引发的一点思考
可能到现在,dropout为啥能防止过拟合这个问题还没有严谨的数学证明,但是不妨碍它的普遍应用,毕竟在很多实验上已经验证了该方法的有效性。Dropout和其他很多调参方法类似,虽然它们的效果很多没有严格的数学证明,我们无法理解背后的奥秘,会调侃为是个玄学,但是这并不能说我们走上了一条不靠谱的路。
举个物理学界的一个很有名的例子,物理学中有个光的波粒二象性的概念。光到底是波还是粒子,是一个争论两三百年的问题,还导致在光的定性这个问题上,直接分为波动说学派和微粒说学派。这两三百年里,牛顿、惠更斯、麦克斯韦、赫兹、普朗克、爱因斯坦、德布罗意、海森堡等每个时代最好的物理学家都做了很多实验,产生过很多争论。直到20世纪初,才得出光的波粒二象性的结论。
连物理学界这种需要严格理论科学基础的学科都会碰到从猜想到实验证明到理论统一的过程,对某些问题,这个过程甚至需要几百年的时间,更何况统计机器学习、深度神经网络这种年轻的研究方向。也许现在深度学习的发展走在一条合适的路上,也许没走在一条合适的路上,这问题只能以后来总结,但现在只能往前探索推进。当对问题了解的更全面时,那会就不再会是盲人摸象了。此外,虽然现在没能证明dropout等方法为啥能防止过拟合,但也许将来就有数学工具来证明。
参考文章:
Machine Translation
上个月Facebook刚发表《Convolutional sequence to sequence learning》,提出用CNN做机器翻译的模型(ConvS2S),模型效果比去年Google基于LSTM做的机器翻译模型(GNMT)的效果更好。没想到这么快,Google又提出一个效果更好的模型,这个模型本身并不复杂,但想法更大胆更直接,不用CNN和RNN,全部用attention。用attention处理远距离依赖,捕获全局信息。
- Attention Is All You Need
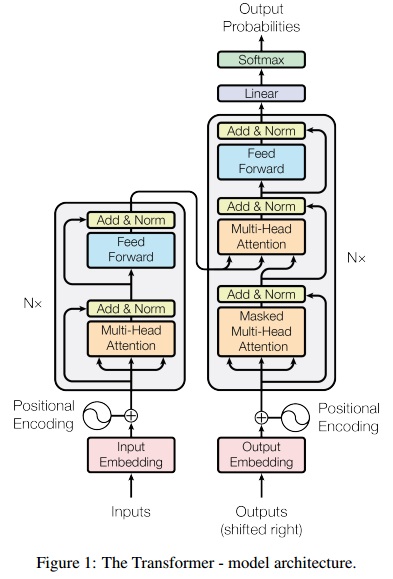
- 提出 scaled dot-product attention 和 multi-head attention 。这两种是整个encoder-decoder模型(作者形容为Transformer模型,参见图1)的核心,也是本文的创新之处。此外,框架还包括residual connection,layer normalization, 全连接层,positional encoding等常用模块。在正则化方面,使用了3种正则化技术,residual dropout(节点的保留概率配置为0.9),attention dropout 和 label smoothing 。
- 上述2种attention自身不带要学习的参数,仅仅是有若干需要在验证集上调试的超参数。过去一些NMT模型对attention是要建立神经网络模型,这会引入更多的要学习的参数。所以有了这对比,足见Transformer模型的简洁。
- 文章还从 complexity per layer 和 maximum path length 等方面说明 self-attention 是简单可依赖的,有关这块的详情可以阅读paper的第4节及表1的数据。
原创文章,转载请注明:转载自vividfree的博客
本文链接地址:201706 阅读笔记